Databricks on AWS Is Becoming the Default Enterprise Data Stack. Is Your Delivery Practice Ready?
Enterprise data architecture decisions have been consolidating quietly over the past two years. Large organisations across financial services, retail, healthcare, and manufacturing have moved past the evaluation phase on data platform strategy. Many of them have landed in the same place: Databricks running on AWS, with Amazon EMR providing the managed Spark compute layer and PySpark as the primary engineering interface. This is not a prediction about where enterprise data infrastructure is heading. It is a description of where it has already arrived. The question that matters now for delivery partners and MSPs is what that decision means for the people they need to place, the engagements they need to staff, and the delivery capacity they need to have available when the next contract lands.
This article is written for MSP leaders, channel delivery directors, and technology practice heads who are responsible for resourcing and executing data engineering engagements. If you are evaluating your delivery bench capacity for 2026 data contracts — particularly those involving Databricks on AWS — this is directly relevant to your planning decisions.
1. Why Databricks on AWS Has Won the Enterprise Conversation
The Databricks Lakehouse architecture on AWS has become the dominant enterprise data platform pattern because it resolves the central tension in data infrastructure — the trade-off between the flexibility of a data lake and the governance of a data warehouse — without requiring organisations to choose between them.
The traditional enterprise data architecture debate ran along two lines. On one side, data warehouses — Amazon Redshift, Snowflake — offered structured, governed environments with strong query performance. On the other, data lakes built on S3-based architectures offered scale and cost efficiency but created data quality and governance problems that compounded over time. Data engineering teams spent years managing the friction between the two.
The Databricks Lakehouse pattern, anchored by Delta Lake, collapses this trade-off. Delta Lake brings ACID transactions, schema enforcement, and time-travel auditing to cloud object storage — meaning organisations get warehouse-grade governance at data-lake-grade scale. For enterprises already invested in AWS infrastructure, this was the decisive factor.
On AWS specifically, Databricks integrates with the managed compute layer that most large enterprises already have in production: Amazon EMR (Elastic MapReduce). This integration means enterprises are not choosing Databricks instead of AWS — they are running Databricks within AWS, alongside S3, Glue, Redshift, and CloudWatch. For enterprise procurement teams, this matters considerably. The stack does not replace existing cloud investment; it extends it.
The result is a coherent, enterprise-proven architecture that has won the confidence of procurement committees, security governance teams, and data engineering leadership simultaneously. For delivery partners, the implication is direct: if you are delivering data engineering work for enterprise clients, this is the stack you are being asked to operate in.
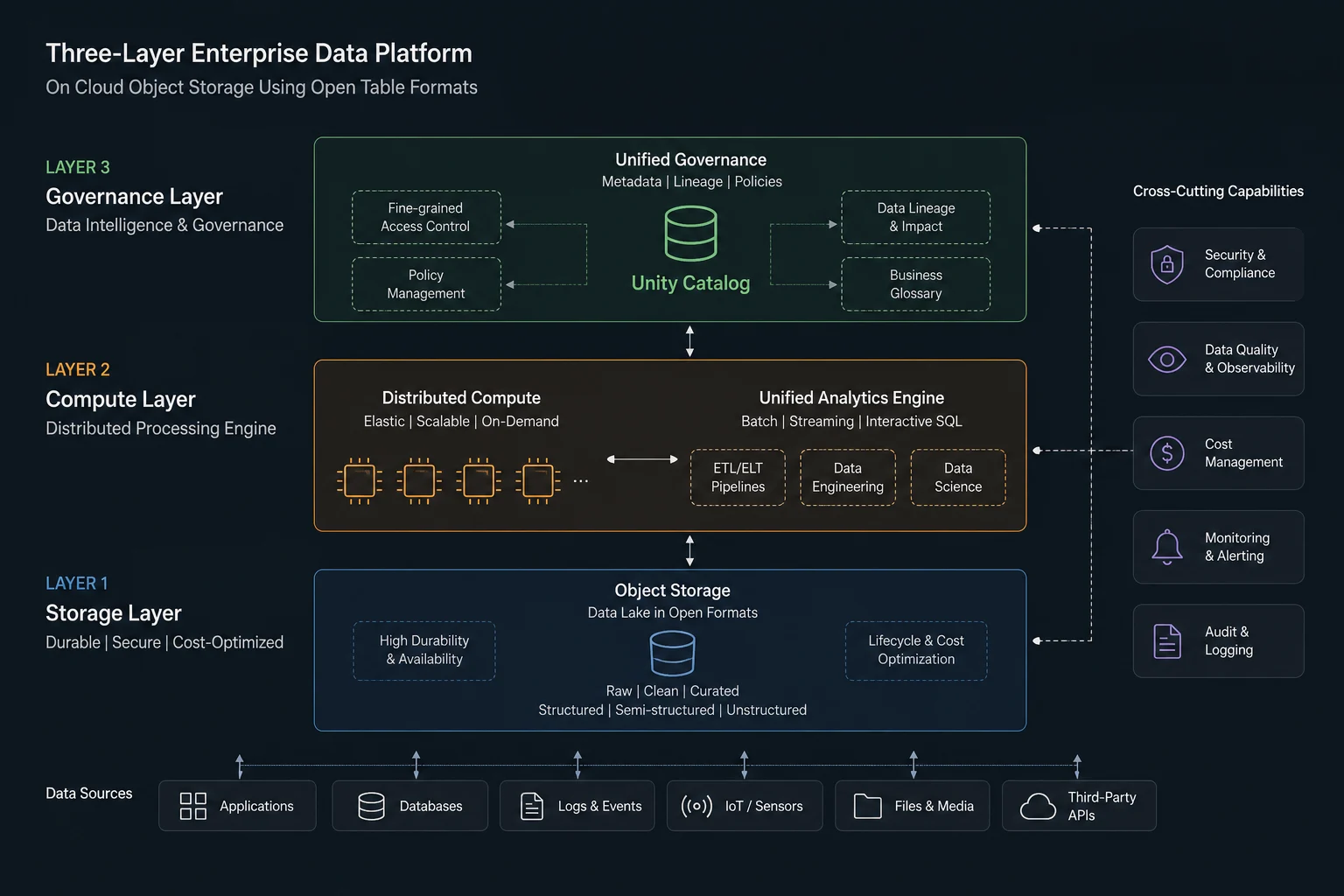
What is the Databricks Lakehouse architecture on AWS?
The Databricks Lakehouse on AWS is an enterprise data platform that combines the scalability and cost efficiency of Amazon S3 cloud object storage with the data quality, ACID transaction support, and governance capabilities of a structured data warehouse — using the open-source Delta Lake table format as its foundation. It runs natively within AWS infrastructure, integrating with Amazon EMR (Elastic MapReduce) for managed Apache Spark compute, alongside services including AWS Glue, Redshift, and CloudWatch. This unified architecture allows enterprises to serve analytics, machine learning, and operational workloads from a single platform — without maintaining separate systems for each use case.
2. What the Databricks AWS Lakehouse Stack Actually Means in Practice
For delivery teams, the Databricks AWS Lakehouse stack is not an abstract platform concept — it is a specific set of tools, patterns, and engineering disciplines that a qualified practitioner must know how to operate together. Understanding how each component interacts is what separates a credible practitioner from a generalist with the right keywords on a CV.
The core components of the stack in a typical enterprise Databricks on AWS engagement:
- Apache Spark — the distributed compute engine that processes data at scale
- PySpark — the primary Python interface for data transformation and pipeline engineering
- Amazon EMR — the managed Spark runtime on AWS, handling cluster provisioning, scaling, and cost management
- Delta Lake — the open-source storage layer providing ACID transactions and schema governance on S3
- Databricks Unity Catalog — data governance, lineage tracking, and access control at the platform level
- Apache Airflow or Databricks Workflows — orchestration for pipeline scheduling and dependency management
The failure mode in under-qualified Databricks placements is consistent. An engineer who has worked with PySpark in isolation but has never built and governed a Delta Lake pipeline at production scale. An engineer who has used Databricks notebooks in a sandbox environment but has never managed EMR cluster configuration for a cost-sensitive enterprise workload. An engineer who understands Spark transformations but has never implemented Unity Catalog governance policies for a regulated industry client. Each of these gaps surfaces within the first sprint.
The table below shows how the Databricks Lakehouse on AWS compares to the two most common alternative platforms partners encounter in enterprise data engineering briefs:
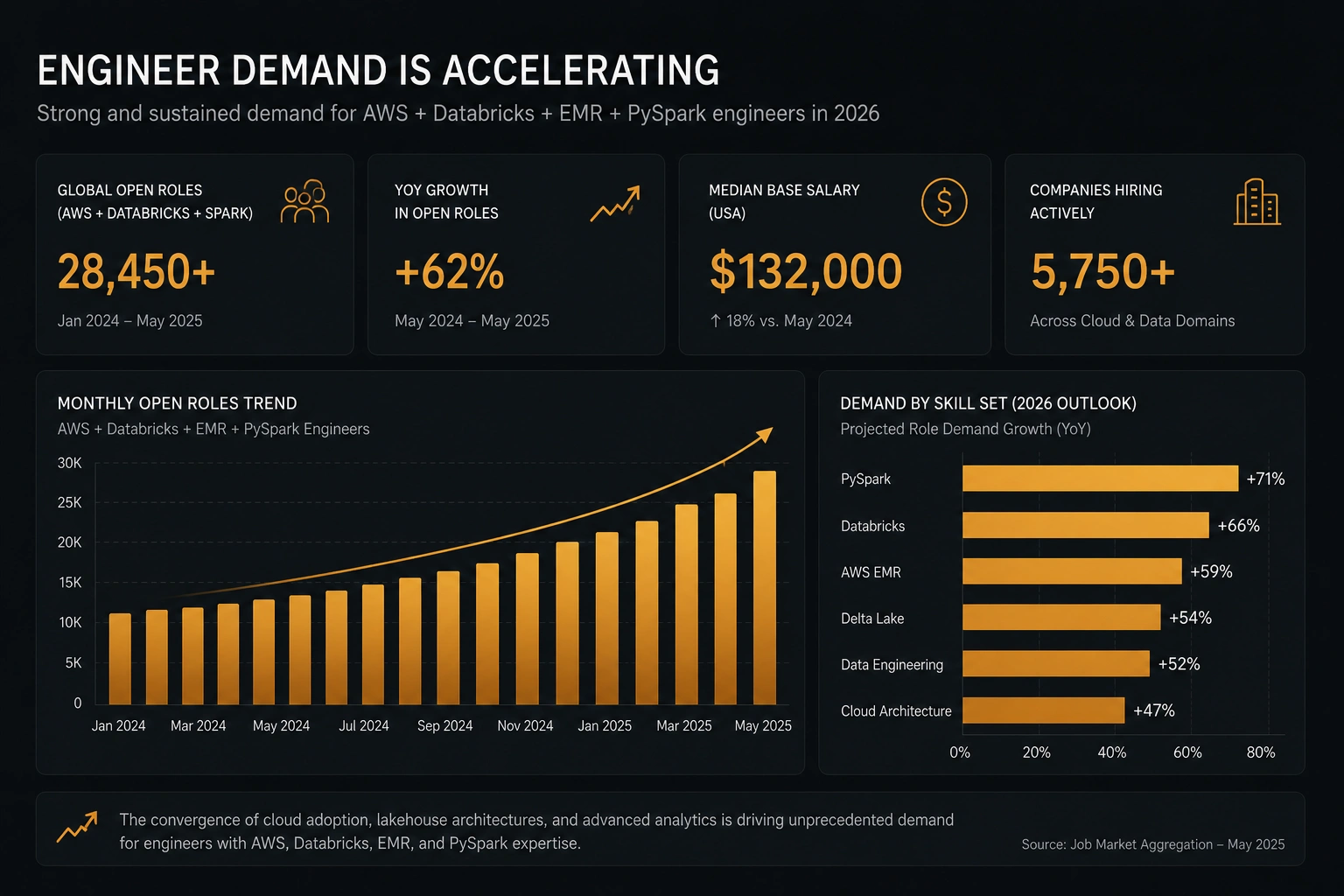
3. The Demand Picture in 2026: What the Numbers Tell Us
The volume of open roles for AWS Databricks EMR PySpark engineers in 2026 is a direct indicator of committed enterprise investment — not projected demand. These are live positions attached to funded programmes, not forward-looking hiring plans.
AWS Databricks roles
live on Indeed (US)
3,258
Open Databricks
engineer roles
$200k+
Senior salaries in
SF, Seattle, New York
Data engineer roles
feature Apache Spark
The demand is not evenly distributed across industries. In the United States, financial services, healthcare, and large-scale retail are the dominant sectors driving Databricks on AWS adoption. In Europe — particularly the United Kingdom, Germany, and Poland — financial services and manufacturing are the primary enterprise buyers. London senior roles frequently exceed £120,000, with Germany offering contractor rates of €75–€110 per hour for senior Databricks practitioners.
The concentration of demand in regulated industries carries a specific implication for delivery partners. Financial services and healthcare engagements bring compliance requirements, data governance mandates, and security audit frameworks that further narrow the qualified practitioner pool. An engineer who is technically proficient but unfamiliar with regulated data environments is not a viable placement for a banking or healthcare data engineering contract.
The mismatch between enterprise procurement decisions and available delivery capacity is not created by a general shortage of data engineers. The data engineering talent market is substantial. The shortage is specific — a shortage of practitioners with production depth across the full Databricks on AWS stack, in the right regulatory context, available within the delivery window that enterprise contracts impose.
SCENARIO — A typical brief, arriving faster than the bench can respond
An MSP wins a six-month data modernisation contract with a financial services client. The scope requires Databricks on AWS with EMR-backed PySpark pipelines and Delta Lake governance frameworks. The partner’s internal bench has three data engineers — two with Snowflake backgrounds, one with Azure Databricks experience. None of the three have worked with Amazon EMR in a production context. The delivery window opens in three weeks. The search starts the day after the contract is signed.
4. The Engineer Profile at the Centre of Every Databricks AWS Engagement
The AWS Databricks EMR PySpark data engineer is a specific delivery profile — not a generalist job title that happens to list these tools. What distinguishes a practitioner who can deliver from one who can describe the stack comes down to verified, production experience across three technical disciplines simultaneously.
Technical depth required in a credible Databricks AWS practitioner:
- EMR cluster configuration, scaling strategy, and cost optimisation at production scale
- PySpark data processing — both batch pipeline engineering and streaming workloads
- Delta Lake implementation — ACID transactions, schema evolution, time-travel audit patterns
- Databricks Unity Catalog — access control policies, data lineage tracking, classification frameworks
- Pipeline orchestration — Databricks Workflows or Apache Airflow in production environments
- AWS-native integration — S3, Glue, Redshift, CloudWatch, IAM, VPC security controls
Technical depth alone is not sufficient in a partner-led delivery context. An engineer placed into an MSP engagement is representing the partner in front of the end client. Their ability to communicate pipeline architecture decisions in accessible language, flag risks before they become escalations, document changes accurately, and operate within a structured sprint cadence determines whether the engagement succeeds — regardless of their PySpark proficiency in isolation.
This is the core rationale behind
Neural Index certification
. Engineers scored by the Neural Index are assessed across Technical Mastery, Communication Fit, and Delivery Readiness — with a minimum threshold of 80 required across all three dimensions before deployment approval.
Neural Index — Delivery Readiness Scoring
Engineers scored by the Neural Index are assessed across Technical Mastery, Communication Fit, and Delivery Readiness.
5. What Delivery-Ready MSPs Are Doing Differently Right Now
The MSPs positioned to win and deliver Databricks on AWS contracts in 2026 are not waiting for the project brief before building bench capacity. They are making stack-specific resourcing decisions ahead of the procurement cycle — operating on the basis that a confirmed brief deserves a shortlist, not a search.
Stack-specific bench investment
Rather than maintaining a generalist data engineering bench and sourcing reactively to brief, forward-looking partners are building explicit capacity in the Databricks on AWS pattern. This means maintaining pre-vetted practitioners on a shortlist that can be activated within 72–96 hours of a contract award — not a pipeline that starts from zero when the brief arrives.
Delivery governance from day one
Every EliteSquad engagement assigns a named Delivery Manager before the first sprint begins. This is not a coordination role — it is a governance layer that manages sprint cadence, risk reporting, milestone accountability, and client-facing communication on the partner’s behalf. Partners who deploy engineers without this governance layer consistently encounter escalations that would have been preventable with structured oversight in place from the start.
Honest pre-sales scoping
Delivery-ready partners understand — before they submit a proposal — the difference between a Databricks engagement they can staff within 14 days and one that requires a 30-day ramp. They communicate that distinction during pre-sales rather than discovering it post-contract. This single behaviour separates partners who retain clients at renewal from those who lose them.
SCENARIO — The same contract, two different outcomes
Two partners pitch the same financial services client on a Databricks data modernisation programme. Partner A proposes a six-week start date, knowing they need to source an engineer from scratch. Partner B confirms deployment within 14 days, with a named Delivery Manager assigned from the first sprint and a pre-vetted Databricks AWS practitioner already on the shortlist. The procurement decision is made on certainty of delivery — not on day-rate. Partner B wins the contract.
Data Engineering Squad — delivery model and capabilities
Learn more about the EliteSquad data engineering delivery practice and how the Data Squad model works.
6. The Window Is Open — And It Has a Shape (2026)
Enterprise platform standardisation cycles are not permanent conditions. The period we are in now — in which enterprises are actively committing to Databricks on AWS and delivery capacity has not yet fully caught up — is a defined window, not an open-ended opportunity.
Enterprise procurement in data infrastructure follows a recognisable pattern. The evaluation phase gives way to a commitment phase, in which contracts are awarded at volume. The commitment phase gives way to a normalisation phase, in which the platform becomes standard practice, the practitioner pool deepens, and the margin available to early movers compresses as more delivery partners build the same capacity.
The Databricks on AWS commitment phase is happening now. The normalisation phase will follow — it always does.
Two things are simultaneously true in 2026. Enterprise demand for qualified AWS Databricks EMR PySpark practitioners is at its highest recorded level — with nearly 4,000 live roles on a single platform at any given time. At the same time, delivery partners who can demonstrate stack-specific bench capacity and a governed delivery model are winning contracts that less-prepared partners are conceding before the first conversation.
The partners who are reading this in 2026 and building Databricks-specific delivery capacity now are positioning themselves as the delivery backbone for the next wave of enterprise data programmes. The partners who wait until the brief arrives are staffing at market cost, in competition with every other partner who waited.
The partners who are reading this in 2026 and building Databricks-specific delivery capacity now are positioning themselves as the delivery backbone for the next wave of enterprise data programmes. The partners who wait until the brief arrives are staffing at market cost, in competition with every other partner who waited.
The platform decision has already been made by the enterprise. The delivery gap belongs to the partner.
The platform decision has already been made. The delivery gap is in finding the right engineer fast enough to matter.
Neural Alliance — partner network
EliteSquad operates as a partner-only delivery backbone through the Neural Alliance partner network.
Contact EliteSquad — get your shortlist
Get your Databricks engineer shortlist in 72 hours.
Frequently Asked Questions