Agentic AI Does Not Replace Data Engineers. It Raises the Bar for What They Need to Know.
In conversations with MSPs and channel partners across the US, EU, and APAC in 2026, we are hearing the same set of objections with increasing frequency. They are fair questions. They deserve honest, research-backed answers — not a defensive response from a company that places data engineers for a living.
This article addresses the five most common objections we hear directly. We will tell you what agentic AI and AI orchestration genuinely do well. And we will show you — with data, not opinion — why that makes skilled data engineers and cloud engineers more important in 2026, not less.
The short answer: AI is the engine. Data is the fuel. Cloud is the road. You cannot run one without the other two.
MSPs and channel partners who are evaluating AI investments, being asked by clients to reduce their data and cloud engineering headcount, or trying to build an honest answer to the question: in an AI-first world, what do human engineers actually do?
What Agentic AI and AI Orchestration Actually Do Well
Before addressing the objections, we want to be direct about something: agentic AI and AI orchestration frameworks are genuinely powerful. Dismissing them would be dishonest — and would undermine the credibility of everything that follows.
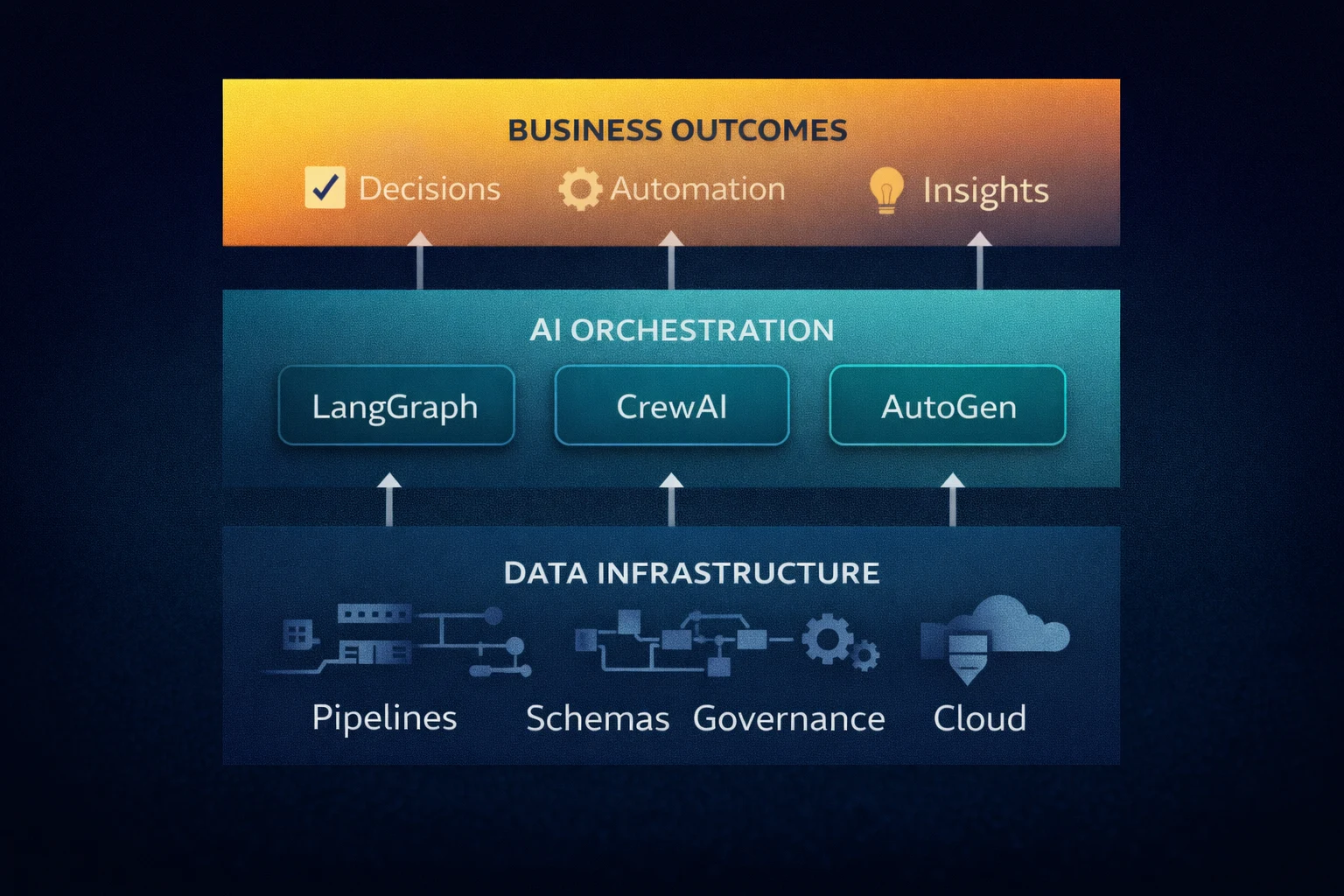
AI orchestration frameworks like LangGraph, CrewAI, and AutoGen are production-stable in 2026. LangGraph handles complex stateful workflows with fine-grained control. CrewAI enables collaborative role-based agent systems with minimal setup. AutoGen supports multi-agent conversations that can reason, plan, and execute tasks autonomously. These are not prototypes. They are infrastructure.
What these frameworks genuinely do well:
- Write pipeline code significantly faster than a human engineer — reducing SQL model development time by up to 50%
- Accelerate code reviews from hours to minutes in controlled environments
- Automate repetitive data transformation tasks that previously required manual engineering effort
- Enable 40% faster pipeline development on well-structured, well-governed data
- Orchestrate multi-step workflows across tools, APIs, and data sources without human intervention at each step
The operative phrase in every one of those bullet points is the qualifier at the end. Faster on well-structured data. Better on well-governed pipelines. More powerful in controlled environments. The AI performs at its best when everything beneath it has been built correctly. That is the whole point.
40%
faster pipeline development
when AI agents are used on governed data
40%+
of agentic AI projects
Gartner predicts over 40% of agentic AI projects will be cancelled by 2027. The reason is not the model. It is the infrastructure and data beneath it.
Building an AI-ready data practice for your clients?
EliteSquad places Neural-Certified data and cloud engineers who understand AI workloads.
The 5 Objections — and the Honest Answers
These are the exact questions we hear from MSPs and channel partners. We are addressing them directly, with research behind every answer.
“AI can write pipeline code itself. Why do we still need a data engineer?”
AI can write pipeline code. What it cannot do is decide what the pipeline should achieve, ensure the source data is clean and trustworthy, design the schema that the pipeline feeds into, or govern what happens when the pipeline breaks at 3am. Writing code is one task within data engineering. The role encompasses architecture, data modelling, quality governance, lineage tracking, and production support. AI accelerates the code-writing portion. It does not replace the engineering judgment that determines whether the code is solving the right problem.
“AI orchestration handles data flow automatically. We do not need someone managing it.”
AI orchestration frameworks like LangGraph, CrewAI, and AutoGen manage workflow execution — not data infrastructure. The orchestration layer assumes the data it retrieves is clean, structured, accessible, and governed. Someone has to build and maintain the pipelines, schemas, APIs, and access controls that the orchestration layer depends on. When the orchestration fails — and it will fail — the failure is almost always in the data layer, not the AI layer. An orchestration framework without a data engineer is a car without a fuel system.
“We are moving fully to agentic AI. Our data team is being dissolved.”
The organisations dissolving their data teams in favour of agentic AI are the same organisations appearing in Gartner’s 40% failure statistic. Agentic AI is not a replacement for a data team — it is a new consumer of the data team’s work. In 2026, a significant portion of data consumers will be AI agents rather than human analysts. That shift demands more sophisticated data infrastructure, not less.
Agents need context, lineage, metadata, and governance frameworks that human analysts never required. Dissolving the data team before building that infrastructure is the most expensive mistake an organisation can make in the AI era.
“AI tools like GitHub Copilot and Cursor already do what data engineers do.”
Copilot and Cursor are coding assistants. They help engineers write code faster. They do not design data architectures, manage cloud infrastructure, govern data quality, or take accountability when a production system fails. Asking whether Copilot replaces a data engineer is like asking whether a calculator replaces a financial analyst. The tool accelerates one specific task within a much broader role. The data engineers who use Copilot and Cursor effectively are more productive — not replaceable.
“Our cloud is fully managed. We do not need cloud engineers anymore.”
Fully managed cloud services — AWS, Azure, GCP — manage the physical infrastructure. They do not design your architecture, optimise your costs, implement your security posture, configure your compliance controls, or make decisions about multi-cloud or hybrid deployments. Every agentic AI system running on cloud infrastructure requires someone who understands how to architect that environment for
AI workloads specifically — vector databases, real-time
data pipelines, GPU compute management, and the networking that connects AI agents to the data they need. Managed cloud is not self-governing cloud.
Real Scenarios: Where AI Alone Was Not Enough
These scenarios reflect patterns we see repeatedly across MSP and channel partner engagements. They are not isolated incidents — they are the normal failure modes of AI projects that underestimated the infrastructure layer.
📋 SCENARIO: The Agentic AI System That Produced Confidently Wrong Answers
A technology firm deployed an agentic AI system to automate reporting for a healthcare client. The AI orchestration layer — built on LangGraph — worked exactly as designed. It retrieved data, processed it, and generated reports autonomously. The problem: the data pipelines feeding the system had not been updated in four months. The AI produced fluent, well-formatted, entirely incorrect reports. The client made three operational decisions based on those reports before the issue was identified. Fixing it required a data engineer to rebuild the pipelines, implement data quality checks, and add freshness validation to every data source the AI accessed.
Lesson: The orchestration was perfect. The infrastructure beneath it was not. The AI performed exactly as designed — on bad data.
📋 SCENARIO: The Cloud Migration That Broke the AI Pipeline
An MSP partner migrated a client from on-premise to Azure cloud. The migration was handled by a managed service — no cloud engineers involved in the design decisions. Six months later, the client deployed an AI agent for supply chain optimisation using Azure OpenAI and a Databricks data platform. The agent failed repeatedly. The root cause: the cloud architecture designed during the managed migration had no consideration for the networking, latency, or data access patterns that AI workloads require. A cloud engineer had to redesign the architecture from scratch — at a cost and timeline that significantly exceeded what proper design upfront would have required.
Lesson: Managed cloud services handle infrastructure. They do not anticipate AI workloads. Architecture decisions made without an engineer compound over time.
📋 SCENARIO: The AI Orchestration System That Could Not Scale
A channel partner built an AI orchestration layer using CrewAI to automate client onboarding for a financial services firm. In testing, it worked flawlessly. In production at 10x the expected volume, it consumed 95% of the API quota on
empty polling calls, hit rate limits within hours, and produced no real-time responsiveness. The problem was the event-driven architecture underneath — or rather, the absence of one. A data engineer had to rebuild the data ingestion layer with proper event streaming before the orchestration layer could function reliably at scale.
Lesson: You cannot build event-driven AI agents on request-response infrastructure. The AI was not the bottleneck. The data architecture was.
The difference between failed and successful agentic AI projects does not stem from weak models — but from undefined agentic workflows, poor plumbing, and unprepared people. — Forrester, 2025
What Has Changed: The Bar Is Higher, Not Lower
The data engineer of 2026 is not doing the same job as 2022. The role has expanded significantly — not disappeared. Here is what has changed:
Building data systems for AI agents, not just human analysts
Traditional data engineering assumed a human at the end of the pipeline — someone who would write SQL queries, build dashboards, and interpret results. In 2026, a significant portion of data consumers are AI agents that need to discover, understand, and utilise data without human intervention. That shift demands a complete rethinking of how data systems are designed. AI agents do not just need data — they need context. They need to understand what the data means, where it came from, how reliable it is, and how it relates to other data. Building that context layer — metadata catalogues, data lineage tracking, semantic layers — is a data engineering problem.
Implementing vector databases and real-time pipelines for AI retrieval
Agentic AI systems that use Retrieval-Augmented Generation (RAG) — the architecture that allows AI agents to retrieve relevant data before responding — require vector databases, embedding pipelines, and retrieval infrastructure that did not exist in most enterprise data stacks three years ago. Building, optimising, and maintaining this infrastructure is data engineering work. It requires understanding both the AI consumption patterns and the underlying data systems simultaneously.
Data engineering roadmap for agentic AI 2026
Governing what AI agents can access and do
Agentic AI systems that operate autonomously require governance frameworks that are fundamentally more complex than those designed for human users. Access controls, permission frameworks, audit trails, compliance layers, and security policies need to be enforced at the infrastructure level — not within the agent’s code. In regulated industries — healthcare, financial services, insurance — this governance work is non-negotiable and legally mandated. It requires data and cloud engineers who understand both the regulatory requirements and the AI system architecture.
Designing and maintaining the cloud infrastructure AI workloads require
AI workloads — particularly those using large language models, vector search, and real-time data retrieval — have infrastructure requirements that are fundamentally different from traditional application workloads. GPU compute management, low-latency networking between data stores and AI models, cost optimisation for inference at scale, and disaster recovery for AI systems all require cloud engineers with specific expertise. Fully managed cloud services do not make these decisions. Engineers do.
See how EliteSquad vets engineers for AI workloads
What This Means for MSPs Building AI Practices in 2026
If you are an MSP evaluating AI investments or being asked to build agentic AI capabilities for your clients, here is the practical implication of everything above:
Your clients' AI projects will fail at the data layer — not the model layer
The most common failure point in agentic AI deployments is not the AI model. It is the data infrastructure beneath it. MSPs who help clients build solid data foundations before deploying AI agents are the ones whose AI programmes succeed. Those who skip the infrastructure work and go straight to the AI layer are the ones appearing in Gartner’s 40% failure statistic.
The engineers you need now are different from the ones you needed in 2022
A data engineer who only knows batch ETL and SQL warehouses is not equipped for the AI era. The engineers MSPs need in 2026 understand vector databases, semantic data layers, real-time pipelines, AI agent consumption patterns, and the governance frameworks that autonomous systems require. This is a smaller talent pool than the one that existed for traditional data engineering — which means the search is harder, the vetting needs to be more rigorous, and the cost of a wrong placement is higher.Agentic AI systems that use Retrieval-Augmented Generation (RAG) — the architecture that allows AI agents to retrieve relevant data before responding — require vector databases, embedding pipelines, and retrieval infrastructure that did not exist in most enterprise data stacks three years ago. Building, optimising, and maintaining this infrastructure is data engineering work. It requires understanding both the AI consumption patterns and the underlying data systems simultaneously.
The Neural Index was designed for exactly this moment
Every engineer EliteSquad places is assessed across Technical Mastery, Communication Fit, and Delivery Readiness — with Technical Mastery specifically evaluating depth in modern stacks including Databricks, Snowflake, Azure Fabric, dbt, and the vector database and streaming infrastructure that AI workloads require.
The Neural Index engineers are not just technically qualified — they are delivery-ready for the
programmes that matter most right now.
Need data or cloud engineers who understand AI workloads?
EliteSquad shortlists Neural-Certified engineers in 72–96 hours. No CVs. A delivery forecast.
Frequently Asked Questions